NVIDIA DGX Spark — prvé spustenie a lokálny LLM inference
Unboxing, OTA update, NVIDIA NIM setup a benchmark Llama 3.1 8B aj Qwen3 32B na DGX Spark. Reálne skúsenosti vrátane problémov.
Do firmy nám dorazil NVIDIA DGX Spark — kompaktný AI server s GB10 GPU a 128 GB unified RAM. V tomto poste ho rozbaľujem, pripájam cez SSH, nastavujem NVIDIA NIM a spúšťam prvý lokálny LLM inference. Žiadne prikrášlenie, aj s problémami, na ktoré som cestou narazil.
Čo je inference? Tréning je fáza, kedy sa AI model učí z dát. Inference je keď tento natrénovaný model používate v praxi. Položíte otázku, model vygeneruje odpoveď. Napríklad keď chatujete s Llama alebo GPT, to je inference. S DGX Spark to beží lokálne, na vlastnom hardvéri, bez odosielania dát tretím stranám.

Prvý boot a OTA update
Na prvý boot máte dve možnosti:
- HDMI + Bluetooth periférie — pripojíte monitor, klávesnicu a myš priamo k Sparku a nastavíte Wi-Fi cez GUI (moja voľba)
- Hotspot — pripojíte sa laptopom na Wi-Fi hotspot Sparku (údaje na štítku v balení) a celý setup urobíte cez webový prehliadač
Po pripojení Sparku na Wi-Fi začne automatický OTA update. Priebeh sledujete cez prehliadač na rovnakej sieti:
http://spark-XXXX.localPre prvé spustenie je jednoduchšie mať Spark aj laptop na rovnakej sieti. Neskôr, keď Spark pripojíte na dedikovaný segment siete, pripájate sa cez IP adresu alebo hostname.
SSH pripojenie
Po dokončení update sa pripojíte cez mDNS hostname. Spark si ho nastaví automaticky:
ssh nvidia@spark-XXXX.localHostname vášho zariadenia zistíte na HDMI obrazovke pri prvom boote, alebo cez mDNS discovery:
# macOS: find Spark on local network
dns-sd -B _ssh._tcp local.Tip: Ak mDNS nefunguje (firemná sieť, device isolation), zistite svoj subnet cez
ifconfiga proskenujte ho na SSH:nmap -p 22 <váš-subnet>/24.
Overenie GPU
Po pripojení cez SSH overte, že GPU je dostupná:
$ nvidia-smi
Mon Mar 23 16:02:30 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.142 Driver Version: 580.142 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
|=========================================+========================+======================|
| 0 NVIDIA GB10 On | 0000000F:01:00.0 On | N/A |
| N/A 41C P8 3W / N/A | Not Supported | 0% Default |
+-----------------------------------------+------------------------+----------------------+NVIDIA GB10, driver 580.142, CUDA 13.0. Všetko ready.
Aký inference engine zvoliť?
Na Spark máte na výber niekoľko inference enginov.
| NIM | Ollama | LM Studio | |
|---|---|---|---|
| Setup | Docker + NGC kľúč | Snap (sudo snap install ollama) | AppImage, GUI |
| Presnosť | FP8 / NVFP4 (TensorRT-LLM) | Q4–Q8, FP16, MXFP4 | Q4–Q8, FP16 |
| Viac používateľov | Škáluje s konkurenciou | Slabé pri konkurencii | Single-user |
| Stav na Spark | GA | Stabilný | Stabilný (od 10/2025) |
Ollama — rýchly štart cez sudo snap install ollama. Podľa Ollama benchmarkov dosahuje na Llama 3.1 8B 25–38 tok/s podľa kvantizácie. Ideálny na prototyping a single-user chatovanie.
NIM — kontajnery s TensorRT-LLM backendom optimalizovaným pre Spark. Používa NVFP4 kvantizáciu pre maximálny výkon na Blackwell GPU. Škáluje lepšie pri viacerých konkurentných requestoch.
LM Studio — funguje na Spark od októbra 2025 cez ARM64 Linux AppImage. Dobrá voľba ak preferujete GUI.
Podrobnejšie porovnanie: Choosing an Inference Engine on DGX Spark, LMSYS DGX Spark Review.
Idem s NIM — zaujímajú ma TensorRT-LLM optimalizácie a chcem to neskôr otvoriť viacerým kolegom.
NVIDIA NIM — setup krok za krokom
1. Pridať používateľa do docker skupiny
Pri prvom spustení si vytvoríte vlastného používateľa. Docker štandardne vyžaduje root práva, preto je potrebné pridať tohto používateľa do skupiny docker:
sudo usermod -aG docker $USER
newgrp docker2. Prijať licenciu modelu na NGC
Na sťahovanie NIM kontajnerov potrebujete bezplatný NGC účet. Pred prvým pullom musíte prijať licenčné podmienky modelu:
- Zaregistrujte sa na NGC (ak ešte nemáte účet)
- Choďte na NGC Catalog
- Nájdite model (napr.
nim/meta/llama-3.1-8b-instruct) - Kliknite Accept / Agree to terms
Dôležité: Bez prijatia licencie
docker pullzlyhá s errorom:DENIED: Please accept license on the browser to be able to download
3. Vygenerovať NGC API kľúč
Na NGC portáli kliknite Generate API Key. Kľúč začína na nvapi-....
4. Docker login do NGC registry
export NGC_API_KEY="nvapi-vas-kluc"
echo "$NGC_API_KEY" | docker login nvcr.io --username '$oauthtoken' --password-stdin
# Expected output: Login SucceededUsername je doslova reťazec $oauthtoken (nie premenná, preto jednoduché úvodzovky). Heslo je NGC API kľúč.
Tip: Ak dostanete
unauthorizederror, skontrolujte či API kľúč nie je expirovaný a vygenerujte nový.
5. Spustiť NIM kontajner
Pre prvý test som zvolil Llama 3.1 8B Instruct — najmenší NIM model dostupný pre Spark (~16 GB download). Rýchlo sa stiahne, nízka VRAM náročnosť a dostatočná kvalita na overenie, že celý stack funguje. Na reálne nasadenie plánujem vyskúšať Qwen3-32B alebo väčší, uvidím podľa výkonu a kvality.
export CONTAINER_NAME=meta-llama-3.1-8b-instruct
export IMG_NAME="nvcr.io/nim/meta/llama-3.1-8b-instruct:latest"
export LOCAL_NIM_CACHE=~/.cache/nim
mkdir -p "$LOCAL_NIM_CACHE"
chmod -R 777 "$LOCAL_NIM_CACHE"
docker run -d \
--name=$CONTAINER_NAME \
--gpus all \
--shm-size=16g \
-e NGC_API_KEY \
-e NIM_SDK_USE_NATIVE_TLS=1 \
-v "$LOCAL_NIM_CACHE:/opt/nim/.nim-cache" \
-p 8000:8000 \
$IMG_NAMEKontajner beží na pozadí (-d). chmod 777 je potrebný, pretože NIM kontajner beží pod userom nim.
Llama 3.1 8B generic NIM nesie model weights priamo v Docker image (~21 GB) — cache adresár zostáva prázdny. DGX Spark varianty (napr. Qwen3-32B) sťahujú optimalizovaný profil po štarte a cache aktívne využívajú. V oboch prípadoch odporúčam mount nastaviť — pri zmene modelu sa cache oplatí.
6. Môžeme taktiež sledovať priebeh
docker logs -f $CONTAINER_NAMEPo stiahnutí uvidíte štart vLLM enginu a načítanie modelu do GPU. Keď sa objaví Application startup complete., NIM je ready.
Kompletný výstup po spustení
$ docker logs -f meta-llama-3.1-8b-instruct
/usr/local/lib/python3.12/dist-packages/torch/cuda/__init__.py:435: UserWarning:
Found GPU0 NVIDIA GB10 which is of cuda capability 12.1.
Minimum and Maximum cuda capability supported by this version of PyTorch is
(8.0) - (12.0)
queued_call()
Starting vLLM v0.17.1
Model: meta/llama-3.1-8b-instruct
Precision: fp8
TP/PP: 1/1
Port: 8000
/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/chat_completion/protocol.py:346:
SyntaxWarning: invalid escape sequence '\e'
/usr/local/lib/python3.12/dist-packages/vllm/entrypoints/openai/completion/protocol.py:176:
SyntaxWarning: invalid escape sequence '\e'
(APIServer pid=23) WARNING 03-26 13:44:45 [modelopt.py:370] Detected ModelOpt fp8
checkpoint (quant_algo=FP8). Please note that the format is experimental and could change.
(EngineCore_DP0 pid=143) /usr/local/lib/python3.12/dist-packages/torch/cuda/__init__.py:435:
UserWarning: Found GPU0 NVIDIA GB10 which is of cuda capability 12.1.
Loading safetensors checkpoint shards: 0% Completed | 0/2 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 50% Completed | 1/2 [00:39<00:39, 39.06s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [01:10<00:00, 34.31s/it]
Loading safetensors checkpoint shards: 100% Completed | 2/2 [01:10<00:00, 35.02s/it]
(EngineCore_DP0 pid=143) 2026-03-26 13:46:20,129 - INFO - flashinfer.jit:
[Autotuner]: Autotuning process starts ...
(EngineCore_DP0 pid=143) 2026-03-26 13:46:22,349 - INFO - flashinfer.jit:
[Autotuner]: Autotuning process ends
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|██████████| 51/51 [00:03<00:00, 15.24it/s]
Capturing CUDA graphs (decode, FULL): 100%|██████████| 35/35 [00:31<00:00, 1.13it/s]
(APIServer pid=23) WARNING 03-26 13:46:58 [model.py:1355] Default vLLM sampling parameters
have been overridden by the model's generation_config.json:
{'temperature': 0.6, 'top_p': 0.9}
(APIServer pid=23) INFO: Started server process [23]
(APIServer pid=23) INFO: Waiting for application startup.
(APIServer pid=23) INFO: Application startup complete.Ctrl+C zastaví len sledovanie logov — kontajner beží ďalej.
Či je NIM ready overíte jednoduchým curl-om:
curl -s http://localhost:8000/v1/models| Odpoveď | Stav |
|---|---|
Connection refused | Kontajner sa ešte štartuje |
502 Bad Gateway | Nginx proxy beží, model sa načítava |
| JSON s modelom | Ready na inference |
Keď je NIM ready, odpoveď vyzerá takto:
{
"object": "list",
"data": [{
"id": "meta/llama-3.1-8b-instruct",
"object": "model",
"owned_by": "vllm",
"max_model_len": 131072
}]
}Pri 8B modeli to trvá 2–5 minút po stiahnutí.
NIM sťahuje dáta v dvoch fázach:
docker pull— stiahne container image (~21 GB)- Po štarte kontajnera — stiahne optimalizovaný model profil pre váš hardware (ďalšie GB)
Obe fázy vyžadujú stabilný internet. Na nestabilnej sieti download zlyhá s error decoding response body a kontajner sa zastaví.
Priebeh sťahovania môžeme sledovať na druhom termináli — každých 5 sekúnd zobrazí veľkosť modelu a stav API:
watch -n5 'docker exec meta-llama-3.1-8b-instruct du -sh /opt/nim/ 2>/dev/null; \
curl -s http://localhost:8000/v1/models 2>&1 | head -3'Počas sťahovania uvidíte rastúcu veľkosť a 502 Bad Gateway:
4.2G /opt/nim/
<html><head><title>502 Bad Gateway</title></head>Keď je model načítaný a API beží:
8.9G /opt/nim/
{"object":"list","data":[{"id":"meta/llama-3.1-8b-instruct",...Ak NIM opakovane padá s error decoding response body, problém je v rýchlosti alebo stabilite siete. Na 100 Mbit/s linke v kancelárii sa mi download opakovane poškodil. Pomohla kombinácia dvoch vecí: preniesť Spark do serverovne s 1 Gbit/s pripojením a pridať -e NIM_SDK_USE_NATIVE_TLS=1 do docker run príkazu — táto premenná zmení TLS implementáciu a pomáha pri problémoch so sťahovaním.

7. Otestovať inference
API je OpenAI-kompatibilné — endpoint /v1/chat/completions:
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta/llama-3.1-8b-instruct",
"messages": [{"role": "user", "content": "Hello, who are you?"}],
"max_tokens": 128
}'Výstup
{
"id": "chatcmpl-b41203406f00d0f2",
"object": "chat.completion",
"model": "meta/llama-3.1-8b-instruct",
"choices": [{
"message": {
"role": "assistant",
"content": "I'm an artificial intelligence model known as a conversational AI. I'm a computer program designed to simulate human-like conversations and answer questions to the best of my knowledge based on my training data..."
},
"finish_reason": "length"
}],
"usage": {
"prompt_tokens": 41,
"completion_tokens": 128,
"total_tokens": 169
}
}8. Zmena modelu
Kontajner zastavíte a spustíte iný model. Ďalší na rade je Qwen3-32B — NIM variant optimalizovaný priamo pre DGX Spark:
docker stop $CONTAINER_NAME
docker run -d \
--name=qwen3-32b \
--gpus all \
--shm-size=16g \
-e NGC_API_KEY \
-e NIM_SDK_USE_NATIVE_TLS=1 \
-v ~/.cache/nim:/opt/nim/.cache \
-p 8000:8000 \
nvcr.io/nim/qwen/qwen3-32b-dgx-spark:1.1.0-variantPozor na cache path: Llama NIM (generic) používa
/opt/nim/.nim-cache, DGX Spark varianty (Qwen3-32B) používajú/opt/nim/.cache. Bind mount treba prispôsobiť podľa variantu.
Čo ďalej?
Spark beží, NIM servuje prvý model. Ale rozmýšľam ďalej — čo s tým reálne robiť?
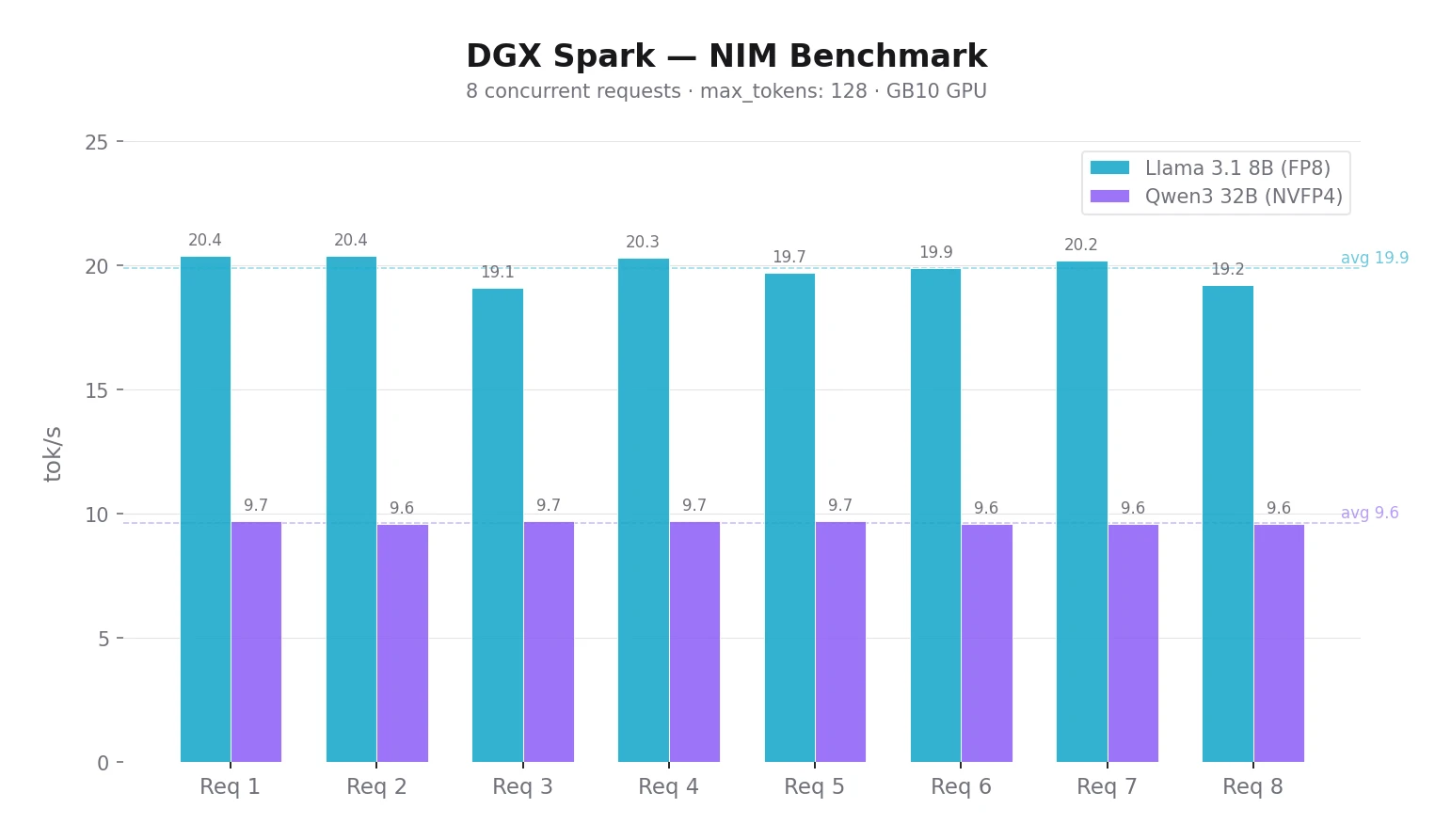
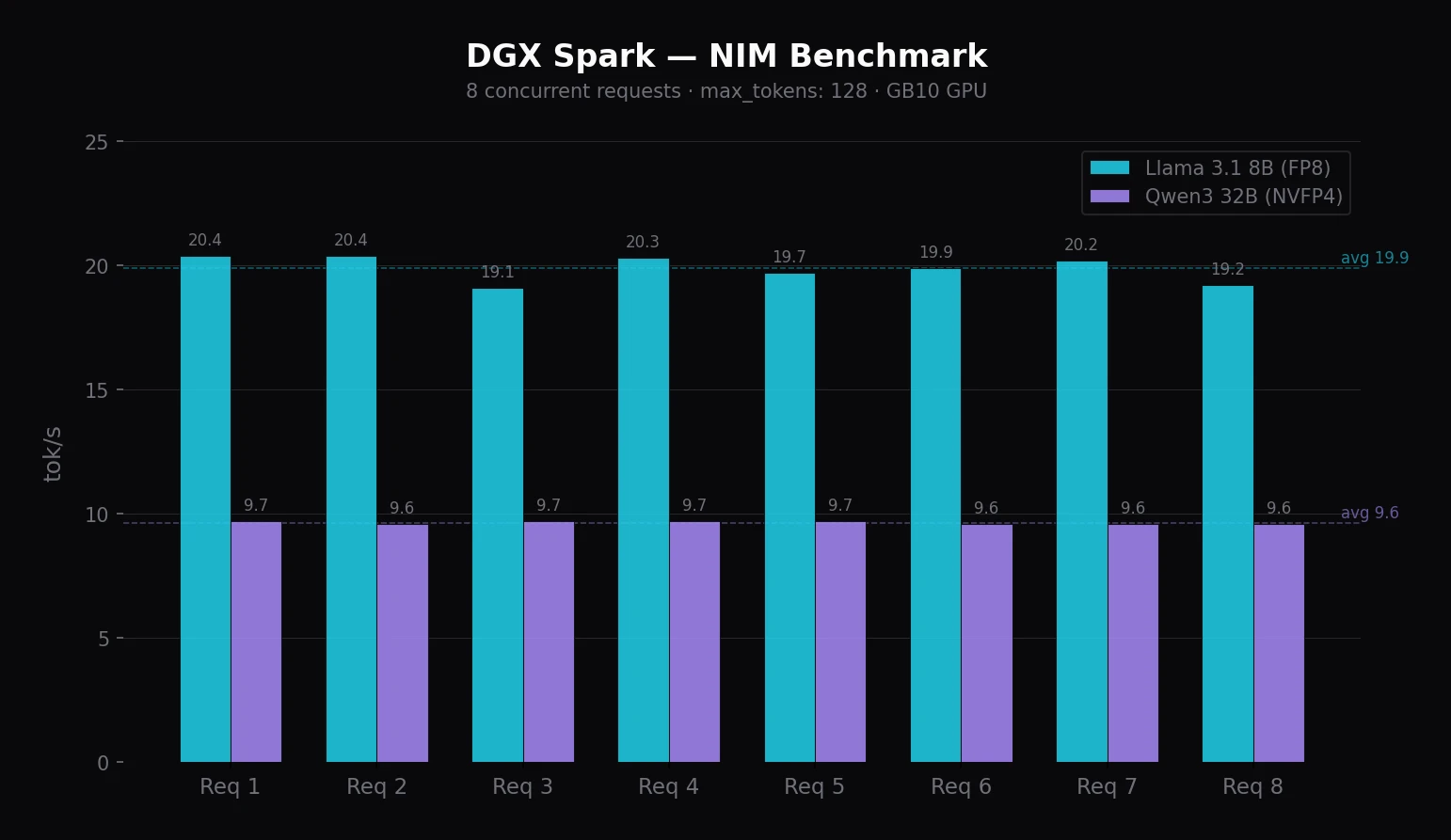
Viac používateľov naraz. NIM rieši batching konkurentných requestov automaticky — netreba nič konfigurovať. Pre 2–4 kolegov s 8B modelom stačí zdieľať URL. V mojom benchmarku Llama 3.1 8B cez NIM zvládla 8 konkurentných requestov pri ~20 tok/s na každý.
Pripravil som skripty na overenie a benchmarking — stačí vytvoriť .env s URL vášho Sparku a spustiť:
Healthcheck — overí či NIM beží a odpovie jedným requestom:
$ ./healthcheck.sh
Testing NIM at http://spark-XXXX.local:8000 (model: meta/llama-3.1-8b-instruct)
---
Response:
I'm an artificial intelligence model known as a large language model (LLM).
I'm a computer program designed to understand and generate human-like text.
I can answer questions, provide information, and even engage in conversation
to the best of my abilities.
---
Tokens: prompt: 41, completion: 124, total: 165Benchmark — konkurentné requesty, meria čas a tok/s:
$ ./benchmark.sh
Benchmark: 8 concurrent requests
Endpoint: http://spark-XXXX.local:8000
Model: meta/llama-3.1-8b-instruct
---
Request 3: 4.17s | 80 tokens | 19.1 tok/s
Request 8: 4.20s | 81 tokens | 19.2 tok/s
Request 5: 4.50s | 89 tokens | 19.7 tok/s
Request 6: 4.61s | 92 tokens | 19.9 tok/s
Request 4: 4.76s | 97 tokens | 20.3 tok/s
Request 2: 4.80s | 98 tokens | 20.4 tok/s
Request 7: 4.80s | 97 tokens | 20.2 tok/s
Request 1: 4.88s | 100 tokens | 20.4 tok/s
---
Done.Pri 8 konkurentných requestoch Llama 8B dosahuje ~20 tok/s, Qwen3 32B ~9.7 tok/s na request — NIM batching funguje. Počet requestov sa dá meniť: ./benchmark.sh 16.
Skripty na stiahnutie: healthcheck.sh · benchmark.sh · .env.example
Open WebUI. Webové rozhranie pre kolegov, ktorí nechcú pracovať cez terminál. NIM má OpenAI-kompatibilné API, takže stačí zadať URL endpointu a funguje.
Multi-node. Podľa NVIDIA dokumentácie je možné prepojiť až 4 Sparky cez RoCE pre väčšie modely. Zatiaľ mám jeden, ale je to zaujímavá možnosť do budúcna.
Záver
DGX Spark je kompaktný, tichý a s 128 GB unified RAM sa zmestí na stôl aj do racku. Initial setup je jednoduchý, ale počítajte s tým, že NIM potrebuje stabilnú a rýchlu linku. Na 100 Mbit/s linke v kancelárii mi NIM download opakovane padal, ani NIM_SDK_USE_NATIVE_TLS=1 nepomohol. Až kombinácia rýchlejšej siete (1 Gbit/s) a tohto TLS flagu to vyriešila.
Po napojení Open WebUI som si oba modely vyskúšal v praxi. Llama 3.1 8B pri ~20 tok/s reaguje plynulo, chatovanie je pohodlné. Qwen3 32B pri ~10 tok/s je na bežný chat citeľne pomalší, ale kvalita odpovedí je vyššia. Pre interaktívnu prácu by som odporučil model s minimálne 20 tok/s. Pomalšie modely majú zmysel skôr pre úlohy na pozadí, kde na rýchlosti nezáleží. Viac porovnaní v ďalšom poste.
Čo som si odniesol:
- Počítajte s initial setupom. OTA update, registrácia na NGC, prijatie licencie, Docker permissions. Nie je to plug-and-play, ale nič neprekonateľné.
- Sieť je kľúčová. NIM download na pomalšej alebo nestabilnej linke opakovane padal. V mojom prípade pomohla 1 Gbit/s linka a
NIM_SDK_USE_NATIVE_TLS=1.
Pre firmu, ktorá chce lokálny LLM inference bez závislosti na cloude, je DGX Spark solídny základ. V ďalšom poste plánujem Open WebUI setup, porovnanie modelov a reálne use cases pre tím.